 有用的涨知识网
有用的涨知识网
听见人声,就能约莫推断你长怎样子?
是的,你没听错!
这是MIT最新科学研究给出的结论。
科学研究相关人员采用数以百万计的大自然网络/ YouTube音频来结构设计和体能训练深度神经网络,实现了从两个人发言的短录音中复建其面部影像。
在体能训练过程中,该数学模型学习了音音频-面部的有关性,这使得它能够聚合影像,捕捉骂人者的各种皮肤特点,比如年纪、异性恋和族群。
这透过利用网络音频中人脸辨识和音音频的大自然共现而以人格监督管理的形式完成,无需隐式地对特性进行建模。
但是也有很多网友对这项科学研究则表示担心:害怕它像deepfake一样被滥用。
原理介绍
当他们在电话里或在收音机里听两个人骂人时,不会看到他/她的脸,他们经常为这个人的相貌建立两个心理数学模型。
词汇与外貌之间存在着密切的联系,这在一定程度上是词汇产生机制的间接结论:年纪,异性恋(影响他们的人声),口腔形状,面部骨骼结构,薄舌头或饱满的舌头 - 所有那些都能影响他们发出的人声。
此外,其他音音频与外貌的关联源于他们骂人的形式:词汇、口音、速度、发音——那些词汇特点往往在不同的民族和文化中共享,而那些特点反过来又能转化为共同的皮肤特点。
MIT此次的科学研究最终目标是判断他们能在多大程度上从两个人骂人的形式推断他的相貌。
具体形式是间接从骂人人的一小段输出音音频短片中,以规范化形式(即,正面,中性表达)间接复建人脸辨识的影像。 图1显示了形式的样本结论。 显然,面部和人声之间没有一对一的匹配。 因此,科学研究最终目标并非预估精确面部的可辨识影像,而是捕捉与输出音音频有关的人的主要面部特点。

图1.上图:从短音音频音音频段复建人脸辨识影像的任务。 下图:Speech2Face数学模型产生的几个结论,它只采用音音频波形作为输出; 真实世界面孔仅供参考。 请注意,科学研究最终目标并非复建人的精确影像,而是恢复与输出音音频有关的特点物理特点。 包括输出音音频在内的所有结论均可在补充材料(SM)中找到。
科学研究相关人员结构设计了两个神经网络数学模型,它将短音音频段的繁杂PtCl作为输出,并预估则表示面部的特点向量。更具体地,面部重要信息由4096-D特点则表示,该特点是从预体能训练的面部辨识网络的依此类推第一层(即,分类层之前的一层)抽取的。
采用单独体能训练的复建数学模型将预估的面部特点音频为人脸辨识的规范化影像。 为了体能训练数学模型采用AVSpeech统计数据集,该统计数据杨锦泉来自YouTube的数千个音频短片组成,其中有超过100,000个不同的人在发言。 科学研究形式是以人格监督管理的形式体能训练,即,它仅采用音频中的音音频和面部的大自然共现,不须要额外的重要信息,比如人类注释。
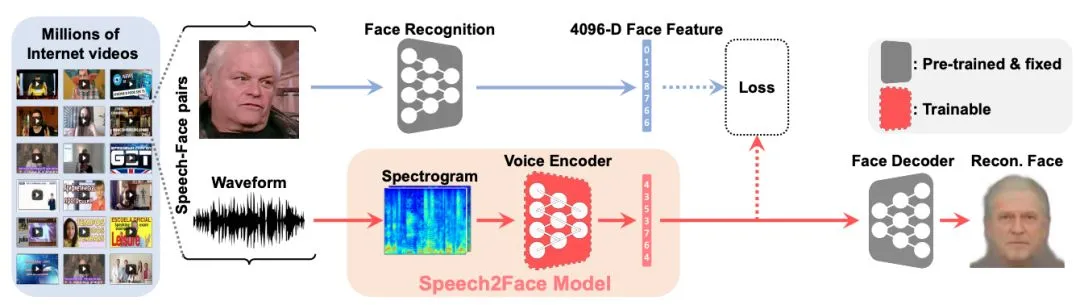
图2. Speech2Face数学模型和体能训练管道。 网络的输出是两个繁杂的频PtCl,是根据两个人骂人的短音音频短片计算出来的。 输出是4096-D面部特点,然后采用预体能训练的面部音频器网络将其音频成面部的规范化影像。 体能训练的模块用橙色盒子标记。体能训练网络回归到透过将人的影像(来自音频的代表性帧)N55XI243SF到面部辨识网络并从其依此类推第一层抽取特点而计算的真实世界面部特点。 数学模型接受了AVSpeech统计数据集中数千个音音频面嵌入对的体能训练。
当然这并非第一次试图从人们的人声中推断有关重要信息。比如,透过词汇预估年纪和异性恋已经得到了广泛的科学研究。 实际上,人们能考虑透过首先从人的人声中预估一些特性(比如,他们的年纪,异性恋等)来将面部影像附加到输出音音频的替代形式,然后从统计数据库获取影像最适合预估的几组特性,或采用特性来聚合两个影像。
但是,这种形式有一些局限性。
首先,从输出信号预估特性依赖于健壮且精确的预测器的存在,并且通常须要用于监督管理的发射塔真实世界标签。 比如,从言辞中预估年纪,异性恋或族群须要构建专门体能训练以捕捉那些特性的预测器。 更重要的是,这种形式将预估的面部限制为仅近似于几组原订义的特性。
此次科学研究关注两个更普遍,更开放的问题:怎样的面部重要信息能从言辞中抽取? 间接从音音频预估完整听觉外观(比如,面部影像)的形式允许他们探索该问题而不限于原订义的面部特点。
具体来说,该科学研究表明复建的面部影像能用作代理来传达人的听觉特性,包括年纪,异性恋和族群。 除了那些主要特点之外,复建揭示了颅面特点(比如鼻子结构)和人声之间不可忽略的有关性。 这是在没有先验重要信息或存在用于那些类型的精细几何特点的精确预测器的情况下实现的。
此外,科学研究认为间接从音音频预估人脸辨识影像可能会支持有用的应用程序,比如根据骂人者的人声将两个代表性的人脸辨识附加到电话/音频呼叫中。
科学研究相关人员最后对重构的不同方面进行了数值评估,包括:仅基于音音频查询检索真实世界面部影像的程度如何; 以及复建的面部影像在年纪,异性恋,族群和各种颅面测量和比例方面与真实世界面部影像(形式未知)的一致程度。

图3. AVSpeech测试集的定性结论。 对于每个例子(三个影像),显示:(左)原始影像,即来自音频的代表性帧在扬声器的面部周围裁剪; (中)从原始影像中抽取的VGG-Face特点的正面化,照明标准化的面部音频器复建; (右)Speech2Face复建结论,透过音频音音频中预估的VGG-Face特点来计算。
数学模型局限
目前该数学模型还不够完善,时不时会作出一些错误预估。

一些故障情况如上图所示。
(a)高音调的男性人声,比如孩子的人声,可能会导致具有女性特点的面部影像。(b)口语与族群不符。(c - d)年纪不匹配。
但总体来说该形式能预估合理的面部,其面部特性与真实世界影像的面部特性一致。 透过间接从这个跨模态特点空间复建面,在听觉上验证了先前科学研究中假设的跨模态生物重要信息的存在。与预估特定特性相反,聚合面部能提供更全面的音音频有关视图,并能开辟新的科学研究机会和应用。
网友:担心被滥用
此科学研究一经发表便引发了广泛关注,很多网友担心其像deepfake一样被滥用。
更有人间接指出,这可能会提供告密者的面部特点(如果获得其音音频)。
但支持者则认为,任何技术都有两面性,这在帮助追捕罪犯方面可能会大有帮助。


对此,你怎么看呢?


.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)

.jpg)
.jpg)
.jpg)
.jpg)
.jpg)

.jpg)
.jpg)
.jpg)

.jpg)